UCCL Optimizations
Chained post
UCCL pre-allocates a wr_ex pool for each RDMAContext, with each chunk corresponding to one wr_ex and links multiple work requests into a chain using wr->next. When sending data and ACKs, only one ibv_post_send is used to send the entire chain to the NIC. This approach reduces the number of doorbell calls and the initialization/allocation overhead of each WR. Combined with TXTracking, it reuses the original wr_ex during retransmission, significantly reducing CPU overhead and improving NIC utilization.
Then I will explain in detail, in combination with the source code in transport.h.
WrExBuffPool
/**
* @brief Buffer pool for work request extension.
*/
class WrExBuffPool : public BuffPool {
static constexpr size_t kWrSize = sizeof(struct wr_ex);
static constexpr uint32_t kNumWr = 4096;
static_assert((kNumWr & (kNumWr - 1)) == 0, "kNumWr must be power of 2");
public:
WrExBuffPool()
: BuffPool(kNumWr, kWrSize, nullptr, [](uint64_t buff) {
struct wr_ex* wr_ex = reinterpret_cast<struct wr_ex*>(buff);
auto wr = &wr_ex->wr;
wr->sg_list = &wr_ex->sge;
wr->num_sge = 1;
wr->next = nullptr;
wr->opcode = IBV_WR_RDMA_WRITE_WITH_IMM;
wr->wr_id = 0;
}) {}
~WrExBuffPool() = default;
};
wr_ex includes the work request wr and Scatter-Gather Element sge. The constructor function initializes each wr in the wr_ex by default, inheriting the original data, and for each wr, only one sge needs to be done, and stores them in a chain-like form.
In class RDMAContext, it has a optional WrExBuffPool. In this way, when sending data, no malloc WQE is performed. Instead, a batch of already initialized wr_ex is taken from wr_ex_pool_and used. Then, the data is organized for batch transmission by modifying sge/imm_data/next.
// Buffer pool for work request extension items.
std::optional<WrExBuffPool> wr_ex_pool_;
TXTracking
class TXTracking {
public:
struct ChunkTrack {
struct ucclRequest* ureq;
struct wr_ex* wr_ex;
uint64_t timestamp;
uint32_t csn;
bool last_chunk;
};
...
inline void track_chunk(struct ucclRequest* ureq,
struct wr_ex* wr_ex, uint64_t timestamp, uint32_t csn, bool last_chunk) {
unacked_chunks_.push_back({ureq, wr_ex, timestamp, csn last_chunk});
}
Each chunk corresponds to a wr_ex, facilitating retransmission and statistics. The unacked_chunks_ stores all the wr_ex that have not been acknowledged, and it is used for Measure the round-trip time (RTT), packet loss, and queue delay, and during retransmission, you can simply retrieve the original wr_ex and resend it (participating in the chained post process again in RDMAContext::try_retransmit_chunk)
Conclusion:
1. By using chain post, many chunks only need a doorbell-like realizationibv_post_send(qpw.qp, wr, &bad)intransport.cc, which can reduce kernel interaction. 2. TheWrExBuffPoolcan help pwith re-initialization to reduce the per-WR overhead 3. ByTXTracking, it useswr_exand retransmission can also continue to use chained post
Scatter gather list
The system separately allocates memory pools for retransmission chunks and retransmission headers. When constructing WQE, the retr_chunk_hdr and the original chunk data are attached to the same sg_list of the WQE using the ibv_sge array. One doorbell is issued by the NIC to "gather" the complete message from multiple scattered addresses. This not only avoids the memory copy of the header and data, but also ensures that the control information and data are atomically delivered in a single operation. At the same time, in combination with the chained post at the upper layer, multiple WQE with SGLs are connected in series and submitted together, significantly reducing CPU overhead and the number of NIC doorbell requests.
Then I will explain in detail, in combination with the source code in rdma_io.h and transport.h.
struct __attribute__((packed)) retr_chunk_hdr {
// Target address for the lost chunk.
uint64_t remote_addr;
uint32_t imm_data;
};
static_assert(sizeof(struct retr_chunk_hdr) == 12,
"retr_chunk_hdr size is not 12 bytes");
/**
* @brief Buffer pool for retransmission chunks (original chunk + retransmission
* header). Original chunk and retransmission header are transmitted through
* scatter-gather list.
*/
class RetrChunkBuffPool : public BuffPool {
public:
static constexpr uint32_t kNumChunk = 4096;
...
RetrChunkBuffPool(struct ibv_mr* mr)
: BuffPool(kNumChunk, kRetrChunkSize, mr) {}
};
class RetrHdrBuffPool : public BuffPool {
public:
static constexpr size_t kHdrSize = sizeof(struct retr_chunk_hdr);
static constexpr uint32_t kNumHdr = 4096;
...
RetrHdrBuffPool(struct ibv_mr* mr) : BuffPool(kNumHdr, kHdrSize, mr) {}
};
Two parts of the data are required for retransmission:
-
A very small retransmission header
retr_chunk_hdr(12 bytes), which contains:remote_addr: Lost chunk - The destination address to be written back on the opposite end;imm_data: The original immediate data for the write operation (including FID/RID/CSN, etc.) -
A complete original chunk of data
In the class RDMAContext, there is a corresponding code.
// Buffer pool for retransmission chunks.
std::optional<RetrChunkBuffPool> retr_chunk_pool_;
// Buffer pool for retransmission headers.
std::optional<RetrHdrBuffPool> retr_hdr_pool_;
// ...
struct ibv_mr* retr_mr_;
struct ibv_mr* retr_hdr_mr_;
ibv_sge is passed in as a parameter in transport.h and ounting by wr->sg_list = sge.In this way, it can sse the scatter-gather list to send multiple buffers at once.
void rc_recv(void* data, int size, struct Mhandle* mhandle,
struct ibv_send_wr* wr, struct ibv_sge* sge,
struct ucclRequest* ureq);
Conclusion:
1. header withRetrHdrBuffPool, data withRetrChunkBuffPool, and each of them is in its own MR. By "gathering" two SGEs at the NIC end into one packet, the CPU does not need to concatenate, nor does it need to combine theretr_chunk_hdrand chunk data into a continuous buffer, thus avoiding additional copying. 2. Since the header and chunk are multiple SGEs of a WQE, they can be guaranteed to arrive together. 3. The dedicatedretr_mr_/retr_hdr_mr_for retransmission does not affect the normal data path MR; the retransmission logic does not need to modify the original sending code; .
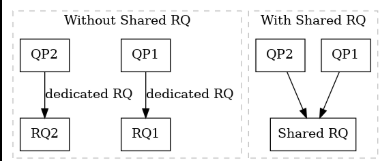
Shared Receive queue
key idea
We know that the foundation of RDMA communication is the Queue Pair (QP), where each QP contains its own Send Queue (SQ) and Receive Queue (RQ). In UCCL’s RDMA design, a major optimization is the use of a Shared Receive Queue (SRQ). Without SRQ, applications with hundreds of QPs must post receive Work Requests (WRs) to every individual RQ, which leads to large and fragmented buffer pools where many RQ entries remain idle. SRQ solves this inefficiency by allowing multiple QPs to share a single unified RQ. All incoming messages across those QPs draw from the same pool of posted receive buffers. This significantly reduces memory consumption and improves scalability, because the receiver only needs to maintain one shared buffer pool sized for the aggregate traffic instead of over-provisioning each connection separately.
Code explaination
Click to expand source code(part 1)
srq_ = util_rdma_create_srq(pd, kMaxSRQ, 1, 0); UCCL_INIT_CHECK(srq_ != nullptr "util_rdma_create_srq failed"); retr_mr_ = util_rdma_create_host_memory_mr( pd, kRetrChunkSize * RetrChunkBuffPool::kNumChunk); retr_hdr_mr_ = util_rdma_create_host_memory_mr( pd, RetrHdrBuffPool::kNumHdr * RetrHdrBuffPool::kHdrSize); // Initialize retransmission chunk and header buffer pool. retr_chunk_pool_.emplace(retr_mr_); retr_hdr_pool_.emplace(retr_hdr_mr_); cq_desc_mr_ = util_rdma_create_host_memory_mr( pd, CQEDescPool::kNumDesc * CQEDescPool::kDescSize); cq_desc_pool_.emplace(cq_desc_mr_); // Populate recv work requests to SRQ for consuming immediate data. inc_post_srq(kMaxSRQ); while (get_post_srq_cnt() > 0) { check_srq(true); }Click to expand source code(part 2)
void SharedIOContext::check_srq(bool force) { auto n_post_srq = get_post_srq_cnt(); if (!force && n_post_srq < kPostRQThreshold) return; int post_batch = std::min(kPostRQThreshold, (uint32_t)n_post_srq); for (int i = 0; i < post_batch; i++) { if (!is_rc_mode()) { auto chunk_addr = pop_retr_chunk(); dp_recv_wrs_.recv_sges[i].addr = chunk_addr; dp_recv_wrs_.recv_sges[i].length = kRetrChunkSize; dp_recv_wrs_.recv_sges[i].lkey = get_retr_chunk_lkey(); dp_recv_wrs_.recv_wrs[i].num_sge = 1; dp_recv_wrs_.recv_wrs[i].sg_list = &dp_recv_wrs_.recv_sges[i]; dp_recv_wrs_.recv_wrs[i].next = (i == post_batch - 1) ? nullptr : &dp_recv_wrs_.recv_wrs[i + 1]; CQEDesc* cqe_desc = pop_cqe_desc(); cqe_desc->data = (uint64_t)chunk_addr; dp_recv_wrs_.recv_wrs[i].wr_id = (uint64_t)cqe_desc; } else { dp_recv_wrs_.recv_wrs[i].num_sge = 0; dp_recv_wrs_.recv_wrs[i].sg_list = nullptr; dp_recv_wrs_.recv_wrs[i].next = (i == post_batch - 1) ? nullptr : &dp_recv_wrs_.recv_wrs[i + 1]; dp_recv_wrs_.recv_wrs[i].wr_id = 0; } } } struct ibv_recv_wr* bad_wr; CHECK(ibv_post_srq_recv(srq_, &dp_recv_wrs_.recv_wrs[0], &bad_wr) == 0); // UCCL_LOG_IO << "Posted " << post_batch << " recv requests for SRQ"; dec_post_srq(post_batch);SRQ Creation: When SharedIOContext is constructed, after creating the CQs, UCCL creates the SRQ and this SRQ is stored in io_ctx->srq_:
srq_ = util_rdma_create_srq(pd, kMaxSRQ, 1, 0);
UCCL_INIT_CHECK(srq_ != nullptr, "util_rdma_create_srq failed");
kMaxSRQ: the maximum number of outstanding receive work requests that the SRQ can hold. This is a constant defining the size of the shared RQ.
-
max_sge = 1: each receive will have at most one scatter-gather element, UCCL posts single-buffer receives. -
srq_limit = 0: this is a threshold for generating anIBV_EVENT_SRQ_LIMIT_REACHEDevent when the number of available WQE falls below a certain value.
Posting receive WRs to SRQ: UCCL pre-posts a number of receive buffers to the SRQ and maintains the pool.
retr_mr_ = util_rdma_create_host_memory_mr(pd, kRetrChunkSize * RetrChunkBuffPool::kNumChunk);
retr_hdr_mr_ = util_rdma_create_host_memory_mr(pd, RetrHdrBuffPool::kNumHdr * RetrHdrBuffPool::kHdrSize);
retr_chunk_pool_.emplace(retr_mr_);
retr_hdr_pool_.emplace(retr_hdr_mr_);
...
cq_desc_mr_ = util_rdma_create_host_memory_mr(pd, CQEDescPool::kNumDesc * CQEDescPool::kDescSize);
cq_desc_pool_.emplace(cq_desc_mr_);
inc_post_srq(kMaxSRQ);
while (get_post_srq_cnt() > 0) {
check_srq(true);
}
For SRQ posting, the retr_chunk_pool_ supplies memory for incoming data.
Then, it calls inc_post_srq(kMaxSRQ) followed by a loop calling check_srq(true) until no more postings are pending.
1. inc_post_srq(n) increments an internal counter of how many receives need posting.
2. check_srq(force=true) call actually posts those receives in batches.
The check_srq(bool force) function is defined in rdma_io.cc either does nothing (if not enough WQEs need posting yet) or, if force==true or the count exceeds a threshold, it will post a batch of WQEs to the SRQ:
void SharedIOContext::check_srq(bool force) {
auto n_post_srq = get_post_srq_cnt();
if (!force && n_post_srq < kPostRQThreshold) return;
int post_batch = std::min(kPostRQThreshold, (uint32_t)n_post_srq);
for (int i = 0; i < post_batch; i++) {
if (!is_rc_mode()) {
// For UC/UD mode:
auto chunk_addr = pop_retr_chunk();
dp_recv_wrs_.recv_sges[i].addr = chunk_addr;
dp_recv_wrs_.recv_sges[i].length = kRetrChunkSize;
dp_recv_wrs_.recv_sges[i].lkey = get_retr_chunk_lkey();
dp_recv_wrs_.recv_wrs[i].num_sge = 1;
dp_recv_wrs_.recv_wrs[i].sg_list = &dp_recv_wrs_.recv_sges[i];
dp_recv_wrs_.recv_wrs[i].next = (i == post_batch-1 ? nullptr : &dp_recv_wrs_.recv_wrs[i+1]);
CQEDesc* cqe_desc = pop_cqe_desc();
cqe_desc->data = (uint64_t)chunk_addr;
dp_recv_wrs_.recv_wrs[i].wr_id = (uint64_t)cqe_desc;
} else {
// RC mode – use empty receives
dp_recv_wrs_.recv_wrs[i].num_sge = 0;
dp_recv_wrs_.recv_wrs[i].sg_list = nullptr;
dp_recv_wrs_.recv_wrs[i].next = (i == post_batch-1 ? nullptr : &dp_recv_wrs_.recv_wrs[i+1]);
dp_recv_wrs_.recv_wrs[i].wr_id = 0;
}
}
struct ibv_recv_wr* bad_wr;
CHECK(ibv_post_srq_recv(srq_, &dp_recv_wrs_.recv_wrs[0], &bad_wr) == 0);
dec_post_srq(post_batch);
}
The loop has two cases:
1. UC/UD mode (!is_rc_mode()): UCCL expects actual data to arrive in the receives.
1. It pops a buffer from the retransmission chunk pool: pop_retr_chunk() provides an available memory buffer address for an incoming data chunk.
2. It sets up an ibv_sge with that address, length and lkey
3. It fills in the recv_wrs[i] with 1 SGE, pointing to this sge, and links the WRE to the next one (except last) using the nextpointer so they form a chain.
4. It also obtains a CQEDesc from a pooland stores the chunk buffer address in it, then uses the pointer to this descriptor as the wr_id for the WQE. The wr_id will be retrieved upon completion to identify the buffer.
2. RC mode (is_rc_mode() == true): In reliable connection mode, UCCL is actually using RDMA Write with immediate for incoming data.The only thing that arrives via the receive queue is the immediate value signaling completion of the write.
1. For RC, UCCL posts a receive WQE with no SGE (num_sge = 0).This is essentially a placeholder just to catch the immediate. No data buffer is needed because the data isn’t delivered via the receive queue.
2. It sets wr_id = 0 and chains them similarly via next.
After constructing the list of WQEs, it calls ibv_post_srq_recv(srq_, first_wr, &bad_wr) to post the chain to the SRQ. The code then decreases the pending post counter by post_batch.This mechanism allows UCCL to efficiently manage receive buffers, adding more when some are consumed.
Conclusion:
In UCCL’s GPU RDMA stack, the Shared Receive Queue is not just a verbs feature; it is the central receive buffer abstraction that lets many UC/UD QPs pull from a single pool of GPU-resident buffers. This design leverages RDMA to minimize CPU involvement, scales to hundreds of QPs per NIC.
reference
-Savir; Zhihu Column; RDMA Shared Receive Queue
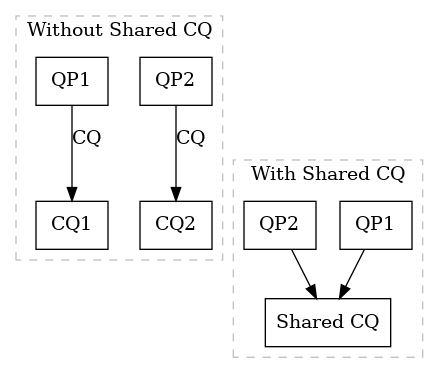
Shared Completion queue
key idea
A Shared Completion Queue (SCQ) means multiple QP use the same CQ to report their work completions, instead of each QP having a dedicated CQ. The motivation is to reduce polling overhead and resource usage – a single thread can poll one CQ for completions from many QPs, rather than polling one CQ per QP. This improves scalability in applications managing numerous connections or flows. By multiplexing all completion events into one queue, SCQs allow faster detection of completed operations and simplify event handling.
Code explaination
Click to expand source code
SharedIOContext(int dev) { support_cq_ex_ = RDMAFactory::get_factory_dev(dev)->support_cq_ex; rc_mode_ = ucclParamRCMode(); auto support_uc = RDMAFactory::get_factory_dev(dev)->support_uc; auto ib_name = RDMAFactory::get_factory_dev(dev)->ib_name; if (rc_mode_) { if (support_uc) { printf( "Using RC on dev %s (per UCCL_RCMODE=1). Note it supports UC, so " "using RC may give less optimized/scalable performance.\n", ib_name); } } else { rc_mode_ = !support_uc; } bypass_pacing_ = ucclParamBypassPacing(); auto context = RDMAFactory::get_factory_dev(dev)->context; auto pd = RDMAFactory::get_factory_dev(dev)->pd; auto port = RDMAFactory::get_factory_dev(dev)->ib_port_num; if (support_cq_ex_) { send_cq_ex_ = util_rdma_create_cq_ex(context, kCQSize); recv_cq_ex_ = util_rdma_create_cq_ex(context, kCQSize); } else { send_cq_ex_ = (struct ibv_cq_ex*)util_rdma_create_cq(context, kCQSize); recv_cq_ex_ = (struct ibv_cq_ex*)util_rdma_create_cq(context, kCQSize); } UCCL_INIT_CHECK(send_cq_ex_ != nullptr, "util_rdma_create_cq_ex failed"); UCCL_INIT_CHECK(recv_cq_ex_ != nullptr, "util_rdma_create_cq_ex failed"); if (support_cq_ex_) { int ret = util_rdma_modify_cq_attr(send_cq_ex_, kCQMODCount, kCQMODPeriod); UCCL_INIT_CHECK(ret == 0, "util_rdma_modify_cq_attr failed"); ret = util_rdma_modify_cq_attr(recv_cq_ex_, kCQMODCount, kCQMODPeriod); UCCL_INIT_CHECK(ret == 0, "util_rdma_modify_cq_attr failed"); } srq_ = util_rdma_create_srq(pd, kMaxSRQ, 1, 0); UCCL_INIT_CHECK(srq_ != nullptr, "util_rdma_create_srq failed"); retr_mr_ = util_rdma_create_host_memory_mr( pd, kRetrChunkSize * RetrChunkBuffPool::kNumChunk); retr_hdr_mr_ = util_rdma_create_host_memory_mr( pd, RetrHdrBuffPool::kNumHdr * RetrHdrBuffPool::kHdrSize); // Initialize retransmission chunk and header buffer pool. retr_chunk_pool_.emplace(retr_mr_); retr_hdr_pool_.emplace(retr_hdr_mr_); cq_desc_mr_ = util_rdma_create_host_memory_mr( pd, CQEDescPool::kNumDesc * CQEDescPool::kDescSize); cq_desc_pool_.emplace(cq_desc_mr_); // Populate recv work requests to SRQ for consuming immediate data. inc_post_srq(kMaxSRQ); while (get_post_srq_cnt() > 0) { check_srq(true); } if (!rc_mode_) { // Create Ctrl QP, CQ, and MR. util_rdma_create_qp( context, &ctrl_qp_, IBV_QPT_UD, support_cq_ex_, true, (struct ibv_cq**)&ctrl_cq_ex_, false, kCQSize, pd, port, &ctrl_mr_, nullptr, CtrlChunkBuffPool::kChunkSize * CtrlChunkBuffPool::kNumChunk, kMaxCtrlWRs, kMaxCtrlWRs, 1, 1); struct ibv_qp_attr attr = {}; attr.qp_state = IBV_QPS_RTR; UCCL_INIT_CHECK(ibv_modify_qp(ctrl_qp_, &attr, IBV_QP_STATE) == 0, "ibv_modify_qp failed: ctrl qp rtr"); memset(&attr, 0, sizeof(attr)); attr.qp_state = IBV_QPS_RTS; attr.sq_psn = BASE_PSN; UCCL_INIT_CHECK( ibv_modify_qp(ctrl_qp_, &attr, IBV_QP_STATE | IBV_QP_SQ_PSN) == 0, "ibv_modify_qp failed: ctrl qp rts"); // Initialize Control packet buffer pool. ctrl_chunk_pool_.emplace(ctrl_mr_); // Populate recv work requests on Ctrl QP for consuming control packets. { for (int i = 0; i < kPostRQThreshold; i++) { ctrl_recv_wrs_.recv_sges[i].lkey = get_ctrl_chunk_lkey(); ctrl_recv_wrs_.recv_sges[i].length = CtrlChunkBuffPool::kChunkSize; ctrl_recv_wrs_.recv_wrs[i].sg_list = &ctrl_recv_wrs_.recv_sges[i]; ctrl_recv_wrs_.recv_wrs[i].num_sge = 1; } inc_post_ctrl_rq(kMaxCtrlWRs); while (get_post_ctrl_rq_cnt() > 0) { check_ctrl_rq(true); } for (int i = 0; i < kMaxAckWRs; i++) { memset(&tx_ack_wr_[i], 0, sizeof(tx_ack_wr_[i])); memset(&tx_ack_sge_[i], 0, sizeof(tx_ack_sge_[i])); tx_ack_wr_[i].sg_list = &tx_ack_sge_[i]; tx_ack_wr_[i].num_sge = 1; tx_ack_wr_[i].opcode = IBV_WR_SEND_WITH_IMM; tx_ack_wr_[i].send_flags = IBV_SEND_SIGNALED; } } } } ~SharedIOContext() { ibv_destroy_cq(ibv_cq_ex_to_cq(send_cq_ex_)); ibv_destroy_cq(ibv_cq_ex_to_cq(recv_cq_ex_)); ibv_destroy_srq(srq_); ibv_dereg_mr(retr_mr_); ibv_dereg_mr(retr_hdr_mr_); }UCCL implements SCQ in its rdma_io.h. The SharedIOContext class encapsulates shared RDMA resources per engine (thread). When a SharedIOContext is created, it allocates one send CQ and one receive CQ and all data QPs will use these, realizing an SCQ.
support_cq_ex_ = RDMAFactory::get_factory_dev(dev)->support_cq_ex;
...
if (support_cq_ex_) {
send_cq_ex_ = util_rdma_create_cq_ex(context, kCQSize);
recv_cq_ex_ = util_rdma_create_cq_ex(context, kCQSize);
} else {
send_cq_ex_ = (struct ibv_cq_ex*)util_rdma_create_cq(context, kCQSize);
recv_cq_ex_ = (struct ibv_cq_ex*)util_rdma_create_cq(context, kCQSize);
}
UCCL_INIT_CHECK(send_cq_ex_ != nullptr, "util_rdma_create_cq_ex failed");
UCCL_INIT_CHECK(recv_cq_ex_ != nullptr, "util_rdma_create_cq_ex failed");
support_cq_ex_. Extended CQs ibv_create_cq_ex allow grabbing extra info like opcode in one shot.
If supported, it creates an extended CQ for send and one for receive with capacity kCQSize.
If not, it falls back to normal CQs (casting them to ibv_cq_ex* pointers for a unified handling).
Thus, send_cq_ex_ and recv_cq_ex_ become the two shared completion queues, one for all send completions, one for all recv completions across QPs. Each is created with flags for single-threaded use and to capture useful fields like in util_rdma_create_cq_ex to ensure the CQEs contain the QP number, immediate data, byte length, etc. This is crucial for demultiplexing events.
Next, when data QPs are created, UCCL attaches the shared CQs to them. In transport.cc, the code uses the SharedIOContext’s CQs for each new QP:
qp_init_attr.send_cq = ibv_cq_ex_to_cq(io_ctx->send_cq_ex_);
qp_init_attr.recv_cq = ibv_cq_ex_to_cq(io_ctx->recv_cq_ex_);
...
qp_init_attr.srq = io_ctx->srq_;
qp_init_attr.qp_type = (rc_mode? IBV_QPT_RC : IBV_QPT_UC);
...
struct ibv_qp* qp = ibv_create_qp(pd_, &qp_init_attr);
UCCL_INIT_CHECK(qp != nullptr, "ibv_create_qp failed for data path QP");
dp_qps_[i].qp = qp;
qpn2idx_.insert({qp->qp_num, i});
io_ctx->record_qpn_ctx_mapping(qp->qp_num, this);
io_ctx->send_cq_ex_and recv_cq_ex_ are the shared CQs created earlier. The code passes them into ibv_create_qp for every data QP it creates.
UCCL keeps track of QP-to-context mapping: after creating each QP, it inserts the QP number into a map qpn2idx_ and a mapping via record_qpn_ctx_mapping that associates the QP number with the RDMAContext it belongs to.
The class centralizes CQ polling entry points poll_ctrl_cq, uc_poll_send_cq, uc_poll_recv_cq, rc_poll_send_cq, rc_poll_recv_cq, which dispatch to extended or normal pollers based on the feature flag to minimize overhead when integrating with different RDMA transports.
int poll_ctrl_cq(void) {
return support_cq_ex_ ? _poll_ctrl_cq_ex() : _poll_ctrl_cq_normal();
}
...
int _rc_poll_recv_cq_normal(void);
int _rc_poll_recv_cq_ex(void);
Conclusion:
1. Benefits of SCQ: A shared completion queue greatly simplifies and speeds up completion handling when many QPs are in use. It reduces the number of CQs the CPU must poll, which in turn cuts down context switches or thread wake-ups and improves cache locality. 2. Trade-off: The main trade-off is complexity in software. The library must demultiplex events (but this is trivial via QP number) and ensure that the shared CQ is large enough to handle bursts from all QPs.